COMP3891
IO Management
IO Devices
There exists a large variety of IO devices:
- Many of them with different properties.
- They seem to require different interfaces to manipulate and manage them.
- We don’t want a new interface for every device.
Challenge:
- Uniform and efficient approach to IO.
Device Drivers

- Drivers originally compiled into kernel.
- Nowadays dynamically loaded when needed.
- Linux modules.
- Number and types vary greatly.
- Even while OS is running (hot-plug USB devices).
- Number and types vary greatly.
- Linux modules.
Role and Requirements of a Driver
- Translate requests through the device-independent standard interface (
open,close,read,write) into appropriate sequence of commands (register manipulations) for the particular hardware.- After issuing command to device, the device either:
- Completes immediately and the driver simply returns to the caller.
- Or, device must process the request and driver usually blocks waiting for an IO complete interrupt.
- After issuing command to device, the device either:
- Initialise the hardware at boot time, and shut it down cleanly at shutdown.
- Must be thread safe as they can be called by another process while a process is already blocked in the driver.
Driver Categories
- Drivers classified into similar categories.
- Block devices and character (stream of data) device.
- OS defines a standard (internal) interface to the different classes of devices.
Driver To Kernel Interface
Major issue is uniform interfaces to devices and kernel:
- Uniform device interface for kernel code.
- Allows different devices to be used the same way.
- Allow internal changes to device driver without fear of breaking kernel code.
- Uniform kernel interface for device code.
- Drivers use a defined interface to kernel services (e.g. kmalloc, etc).
- Allows kernel to evolve without breaking existing drivers.
- Both uniform interfaces together avoid a lot of programming implementing new interfaces.
- Retains compatibility as drivers and kernels change over time.
Acessing IO Controllers
- Separate IO and memory space.
- IO controller registers appear as IO ports.
- Accessed with special IO instructions.
- Memory-mapped IO.
- Controller registers appear as memory.
- Use normal load/store instructions to access.
- Hybrid:
- Both ports and memory mapped IO.
IO Interaction
Programmed IO
- IO module (controller) performs action, not the processor.
- Sets appropriate bits in the IO status register.
- No interrupts occur.
- Processor continually checks status until operation is complete.
- Polling/busy waiting.
Pros:
- Can be efficient if IO completes quickly.
Cons:
- Wastes CPU cycles espeically for long IO actions.
Interrupt Driven IO
- Processor is interrupted when IO module (controller) ready to exchange data.
- Processor is free to do other work.
Pros:
- No needless waiting.
Cons:
- Consumes a lot of processor time because every word read or written passes through the processor.
IO Using Direct Memory Accesss
- DMA controller transfers a block of data directly to or from memory.
- An interrupt is sent when the task is complete.
- Processor only involved at beginning and end of transfer.
Pros:
- Reduces interrupts.
- Less (expensive) context switches or kernel entry-exits.
Cons:
- Requires contiguous regions (buffers).
Interrupt Handlers
- Save registers not already saved by hardware interrupt mechanism.
- (Optionally) set up context for interrupt service procedurre.
- Typically, handler runs in the context of the currently running process.
- No expensive context switch.
- Typically, handler runs in the context of the currently running process.
- Set up stack for interrupt service procedure.
- Handler usually runs on the kernel stack of current process.
- Or nests if already in kernel mode running on kernel stack.
- Ack/Mask interrupt controller, reenable other interrupts.
- Implies potential for interrupt nesting.
- Run interrupt service procedure.
- Acknowledges interrupt at device level.
- Figures out what caused the interrupt.
- Received a network packet, disk read finished, UART transmit queue empty, etc….
- If needed, it signals blocked device driver.
- In some cases, will have woken up a higher priority blocked thread.
- Choose newly worken thread to schedule next.
- Set up MMU context for process to run next.
- Load new/original process’s registers.
- Re-enable interrupt; start running the new process.
Top Half / Bottom Half
Interrupt handlers are split in two:
- Top half:
- Actually responds to interrupt.
- Interrupts are disabled.
- Execution time should be short.
- Most of the complex computation deferred to bottom half.
- Don’t want to miss other interrupts.
- Bottom half:
- Does deferred work (e.g. IP stack processing).
- All interrupts are enabled.
- Allows top half to service a new interrupt while bottom half is still working.
- Cannot sleep, access user space or invoke the scheduler.
Buffering
Buffering improves performance as processes don’t need to read/write a device a byte/word at a time.
- Each syscall adds a significant overhead.
- Process must wait until each IO is complete.
- Blocking/interrupt/waking adds to overhead.
- Many short runs of a process is inefficient.
User Level Buffering
Process specifies a memory buffer that incoming data is placed in until it fills.
- Filling can be done by interrupt service routine.
- Only a single system call, and block/wakeup per data buffer.
- Much more efficient.
Problems:
- If buffer is paged out to disk.
- Could lose data while unavailable buffer is paged in.
- Could lock buffer in memory (needed for DMA), however many processes doing IO reduce RAm available for paging. Can cause deadlock as RAM is limited.
- Consider write case:
- Buffer is available for reuse when:
- Either process must block until potential slow device drains buffer.
- Or deal with asynchronous signals indicating buffer drained.
- Buffer is available for reuse when:
Single Kernel Buffer
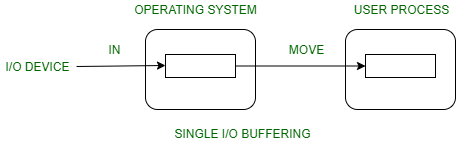
OS assigns a buffer in kernel’s memory for an IO request.
Stream-oriented scenario:
- Used a line at a time.
- User input from a terminal is one line at a time with carriage return signalling the end of the line.
- Output to the terminal is one line at a time.
Block-oriented scenario:
- Input transfers made to buffer.
- Block copied to user space when needed.
- Another block is written into the buffer.
- Can be read ahead to improve performance.
- Swapping can occur since input is taking place in system memory, not user memory.
- OS keeps track of assignment to system buffers to user processes.
Speed up:
- Computation and trasnfer can be done in parallel.
- (No buffering cost) / (Single buffering cost) = (T + C) / (max(T, C) + M).
- Usually M is smaller than T, giving favourable results.
Problems:
- If kernel buffer is full.
- User buffer is swapped out, or
-
Application is slow to process previous buffer.
- Start to lose chracters or drop network packets.
Double Kernel Buffer
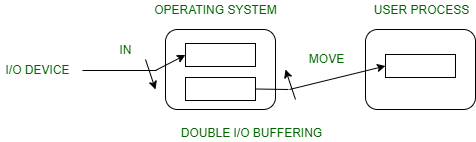
OS uses two kernel buffers instead of one.
- Process can transfer data to or from one buffer whiile the OS empties or fills the other buffer.
Speed up:
- Computation and memory copy can be done in parallel.
- (No buffering cost) / (double buffering cost) = (T + C) / (max(T, C + M)).
Advantages:
- Potential speed up over single buffer.
Disadvantages:
- May be insufficient for really bursty traffic.
- Lots of application writes between long periods of computation.
- Long periods of application computation while receiving data.
- Might want to read-ahead more than a single block for disk.
Circular Buffer
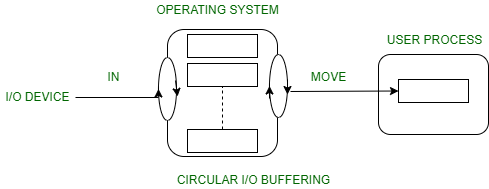
OS uses more than two buffers.
- Generalisation of double buffer.