Hashed File Operations
Overview
Basic idea: use key value to compute page address of tuple.
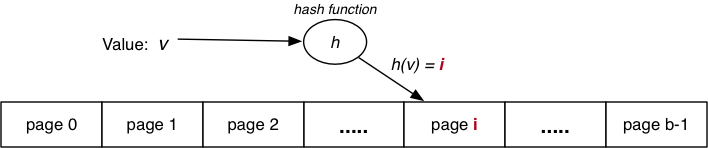
If a bucket for a given hash is full, use overflow pages (much like sorted files).
Hashing Performance
Two important measures for hash files:
- Load factor:
L = r / b = (# of tuples) / (# of buckets).- How full hash file is allowed to get before capacity is increased.
- Average overflow chain length:
b_ov / b = (# of overflow pages) / (# of buckets (aka non overflow pages)).
Three cases for distribution of tuples in a hashed file:
| Case | L |
Ov |
|---|---|---|
| Best | ~= 1 | 0 |
| Worst | » 1 | ** |
| Average | < 1 | 0 < Ov < 1 |
To achieve average case, aim for 0.75 <= L <= 0.9.
Selection with Hashing
Select via hashing on unique key k:
page = getPageViaHash(R, val)
for _tuple in page:
if _tuple.k == val:
return _tuple
for overflowPage in overflowPages(page):
for _tuple in overflowPage:
if _tuple.k == val:
return _tuple
Working out which page given a key:
getPageViaHash(Relation rel, Value key):
h = hash_any(key, len(key))
pid = h % nPages(R)
return get_page(R, pid)
Cost_one:: Best = 1, Avg = 1 + Ov / 2, Worst = 1 + max(OvLen).
Selection on Non-Unique Hash Key nk (pmr)
page = getPageViaHash(R, val)
for _tuple in page:
if _tuple.nk == val:
result.add(_tuple)
for overflowPage in overFlowPages(page):
if _tuple.k == val:
result.add(_tuple)
return result
Cost_pmr = 1 + Ov. Cheap if Ov is small.
Other Queries
Hashing does not help with range queries on selection on attributes which is not the hash key: Cost_range = Cost_one = Cost_pmr = b + b_Ov.
Insertion with Hashing
Insertion uses similar process to one queries:
page = getPageViaHash(R, val)
if room in page:
# insert tuple into page
return
for overflowPage in overflowPages(page):
if room in overflowPage:
# insert tuple into overflow page
return
# add new overflow page
# link new overflow page to previous page
# insert tuple into overflow page
Cost_insert: Best = 1_R + 1_W, Worst = (1 + max(OvLen))_r + 2_w
Deletion with Hashing
Similar performance to select on non-unique key:
page = getPageViaHash(R, val, P)
number_deletions = delTuples(page, k, val)
if n_deletions > 0:
put_page(dataFile(R), page.pid, page)
for overflowPage in overflowPages(page):
n_deletions = delTuples(overflowPage, k, val)
if n_deletions > 0:
put_page(overflowFile(R), overflowPage.pid, overflowPage)
Extract cost over select is cost of writing back modified page.
Method works for both unique and non-unique hash keys.
Problems with Hashing
So far, assumed fixed file size (b).
What file size to use?
- The size we need right now (performance degrades as file overflows).
- The maximum file size we might ever need (significant waste of space).
Problem: change file size => change hash function => rebuild file.
Methods for hashing with files whose size changes:
- Extendible hashing, dynamic hashing (need a directory, no overflows).
- Linear hashing (expands file “systematically”, no directory, has overflows).
Flexible Hashing
All flexible hashing methods:
- Treat hash as 32-bit bit-string.
- Adjust hashing by using more/less bits.
Start with hash function to convert value to bit-string:
uint32 hash(unsigned char *val);
Require a function to extract d bits from bit-string:
uint32 bits(int d, uint32 val);
Use result of bits() as page address.
Splitting

Important concept:
- Consider one page (all tuples have same hash value).
- Recompute page numbers by considering one extra bit.
- If current page is
11, new pages have hashes011and111. - Some tuples stay in page
011(was11). - Some tuples move to page
111(new page). - Also, rehash any tuples in overflow pages of
101.- Likely to reduce the size of the overflow chain.
Result: expandable data file, never requiring a complete file rebuild.