Sorted Files
Overview
Sorted files store records in order of some field k. Makes search more efficient, but insertion less efficient.
Naive implementation:

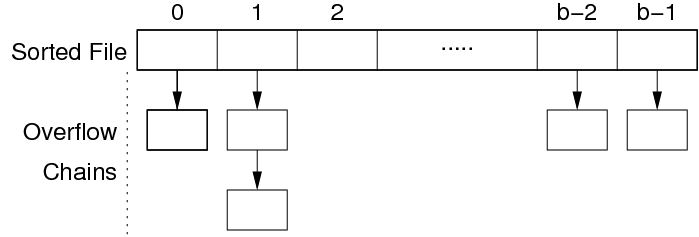
In order to mitigate insertion costs, use overflow pages:
Selection in Sorted Files
For one queries on sort key, use binary search
low, high = 0, nPages(rel) - 1
while low <= high:
mid = (low + high) / 2
(tup, lowVal, highVal) = searchBucket(rel, mid, k, val)
if tup is not None:
return tup
elif val < lowVal:
high = mid - 1
elif val > highVal:
low = mid + 1
else:
return NOT_FOUND
return NOT_FOUND
Search a page and its overflow chain for a key value.
# assumes each page contains index of next page in overflow chain.
def searchBucket(rel, p, k, val):
get_page(rel, p, buf)
(tup, minVal, maxVal) = searchPage(buf, k, val, +INF, -INF)
if tup is not None:
return (tup, minVal, maxVal)
overflowFile = openOvFile(f)
overflowPage = overflow(buf)
while tup is None and overflowPage != NO_PAGE:
get_page(overflowFile, overflowPage, buf)
(tup, minVal, maxVal) = searchPage(buf, k, val, minVal, maxVal)
overflowPage = overflow(buf) # get next overflow page
return (tup, minVal, maxVal)
Search within a page for key; also find min/max key values.
# linear scan, tuples aren't necessarily sorted within a page
def searchPage(buf, k, val, minVal, maxVal):
res = None
for tup in tuples(buf):
if tup.k == val:
res = tup
if tup.k < minVal:
minVal = tup.k
if tup.k > maxVal:
maxVal = tup.k
return (res, minVal, maxVal)
Performance Analysis
Above method treats each bucket like a single large page.
Cases:
- Best: find tuple in first data page we read.
- Worst: full binary search, and not found.
- Examine:
log_2(b)data pages. - Plus examine all of their overflow pages.
- Examine:
- Average: examine some data pages and their overflow pages.
Cost_one: Best = 1, Worst = log_2(b) + b_ov.
Partial Match Retrievals (PMR)
For pmr query on non-unique attribute k, where file is sorted on k.
- Tuples containing
kmay span several pages.
Example:
select * from R where k = 2;
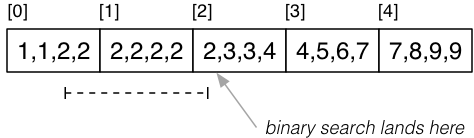
Solution:
- Locate a page
pcontainingk = val(as for one query). - Scan backwards and forwards from
pto find matches.
Cost_pmr = Cost_one + (b_q - 1) * (1 + Ov).
Range Queries on Unique Sort Key
For range queries on unique sort key (e.g. primary key):
- Use binary search to find lower bound.
- Read sequentially until reach upper bound.
Example:
select * from R where k >= 5 and k <= 13;
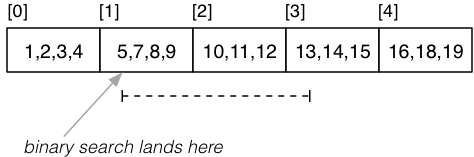
Cost_range = Cost_pmr
Range Queries on Non-Unique Sort Key
For range queries on non-unique sort key, similar method to pmr:
- Binary search to find lower bound (not necessarily first occurrence).
- Go backwards to start of run.
- Go forwards to last occurrence of upper bound.
Example:
select * from R where k >= 2 and k <= 6;
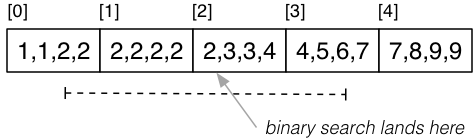
Cost_range = Cost_pmr
Selection on Non-Sort Key
If condition contains attribute j, not the sort key:
- File is unlikely to be sorted by
jas well. - Sortedness gives no searching benefits.
Selection performance in this case is equal to heap files.
Insertion into Sorted Files
Insertion approach:
- Find appropriate page for tuple (via binary search).
- If page not full, insert into page.
- Otherwise, insert into next overflow page with space (possibly creating new page if necessary).
Note: a bucket contains all values within a [minVal, maxVal] range. The pages in a bucket and the tuples in those pages may not necessarily be sorted.
Thus, Cost_insert = Cost_one + δ_w (where δ_w = 1 or 2).
Deletion from Sorted Files
Deletion strategy:
- Find matching tuple(s).
- Mark them as deleted.
Cost depends on selectivity of selection condition. Selectivity determines b_q.
Thus, Cost_delete = Cost_selete + b_qw.