Buffer Pool
Overview of Buffer Pool
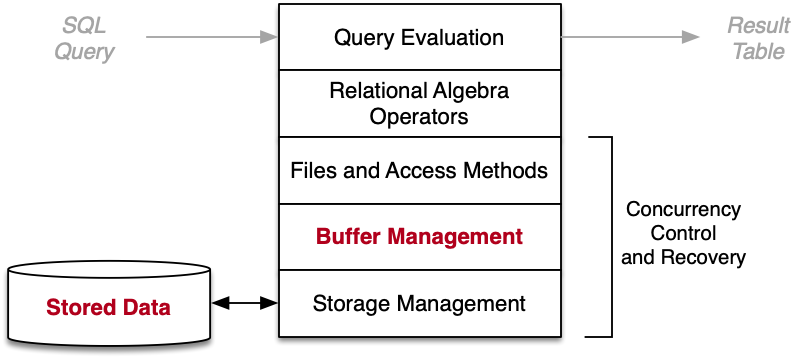
Aim of buffer pool:
- Hold pages read from database files, for possible reuse.
Used by:
- Access methods which read/write data pages.
- E.g. sequential scan, indexed retrieval, hashing.
Uses:
- File manager functions to access data files.

Operations and Data Structures
Main operations:
request_page(pid)(replacesgetBlock()).release_page(pid)(replacesputBlock()).
Data structures:
Page frames[NBUFS].FrameData directory[NBUFS].Pageisbyte[BUFSIZE].
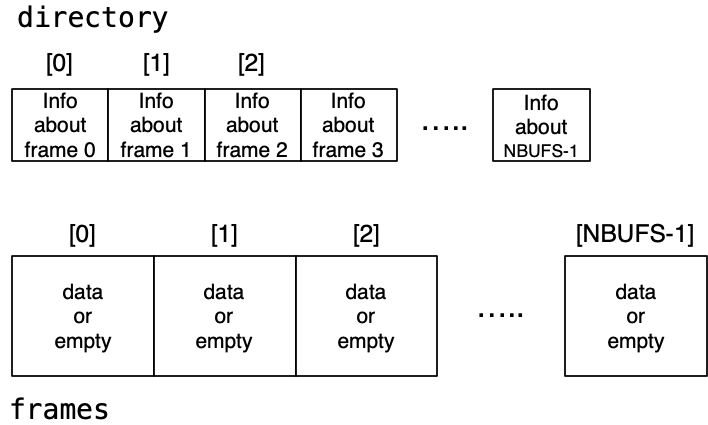
For each frame, we need to know: (FrameData):
- Which
Pageit contains, or whether empty/free. - Whether it has been modified since loading (dirty bit).
- How many transactions are currently using it (pin count).
- Time-stamp for most recent access (assists with replacement).
Pages are referenced by PageID:
PageID = BufferTag = (rnode, forkNum, blockNum).
Scanning
Without buffer pool:
// Requires N page reads.
// If we read it again, N page reads.
Buffer buf;
int N = numberOfBlocks(Rel);
for (int i = 0; i < N; i++) {
PageID pageID = makePageID(db, Rel, i);
getBlock(pageID, buf);
for (int j = 0; j < nTuples(buf); j++) {
process(buf, j);
}
}
With buffer pool:
// Requires N page reads on first pass.
// If we read it again, 0 <= page reads <= N.
Buffer buf;
int N = numberOfBlocks(Rel);
for (int i = 0; i < N; i++) {
PageID pageID = makePageID(db, Rel, i);
int bufID = request_page(pageID); // does not require disk access if page already in buffer pool.
buf = frames[bufID];
for (int j = 0; j < nTuples(buf); j++) {
process(buf, j);
}
release_page(pageID);
}
Implementation Of Page Access Functions
int request_page(PageID pid) {
int bufID;
if (pid in Pool) {
bufID = index for pid in Pool
} else {
if (no free frames in Pool) {
evict a page (free a frame)
}
bufID = allocate free frame
directory[bufID].page = pid;
directory[bufID].pin_count = 0
directory[bufID].dirty_bit = 0
}
directory[bufID].pin_count++;
return bufID;
}
void release_page(pid) {
bufID = index for pid in Pool.
directory[bufID].pin_count--;
}
void mark_page(pid) {
bufID = index for pid in Pool.
directory[bufID].dirty_bit = 1;
}
void flush_page(pid) {
writes specified to page using write_page.
}
Page Eviction
Evicting a page:
- Find frame(s) preferably satisfying:
- pin count = 0 (nobody using it).
- dirty bit = 0 (not modified).
- If selected frame was modified, flush frame to disk.
- Flag directory entry as “frame empty”
If multiple frames can potentially be released:
- Need a policy to decide best choice.
Page Replacement Policies
Common Schemes and Considerations
Several schemes are commonly in use:
- Least Recently Used (LRU).
- Most Recently Used (MRU).
- First in First Out (FIFO).
- Random.
LRU/MRU require knowledge of when pages were last accessed:
- How to keep track of “last access” time?
- Based on request/release operations or on real page usage.
Cost Benefit
Cost benefit from buffer pool (with n frames and b pages to be accessed) is determined by:
- Number of available frames (more ==> better).
- Replacement strategy vs page access pattern.
E.g. 1: sequential scan, LRU or MRU, n >= b:
- First scan costs
breads; subsequent scans are “free”.- No page misses after first scan.
- Very good performance!
E.g. 2: sequential scan, MRU, n < b:
- First scan costs
breads; subsequent scans costb - nreads.- Some page misses after first scan.
- Average performance.
E.g. 3: sequential scan, LRU, n < b.
- All scans cost
breads; known as sequential flooding.- Even page in every scan causes a page miss.
- Very poor performance!
Example Analysis of Buffer Management
Consider the query:
select c.name
from
Customer c,
Employee e
where c.ssn = e.ssn;
This might be implemented in the DBMS via nested loops:
for t1 in Customer {
for t2 in Employee {
if (t1.ssn == t2.ssn) {
append (t1.name) to result set
}
}
}
In terms of page-level operations, the algorithm looks like:
Rel rC = openRelation("Customer");
Rel rE = openRelation("Employee");
for (int i = 0; i < nPages(rC); i++) {
PageID pid1 = magePageID(db, rC, i);
Page p1 = request_page(pid1);
for (int j = 0; j < nPages(rE); j++) {
PageId pid2 = magePageId(db, rE, j);
Page p2 = request_page(pid2);
// compare all pairs of tuples from p1, p2.
// construct solution set from matching pairs.
release_page(pid2);
}
release_page(pid1);
}
Costs depend on relative size of tables, number of buffers (n) and replacement strategy.
Requests: each rC page requested once, each rE page requested rC times.
If nPages(rC) + nPages(rE) <= n:
- Read each page exactly once, holding all pages in buffer pool.
If nPages(rE) <= n - 1, and LRU replacement:
- Read each page exactly once, hold
rEin pool while holding eachrC. - Recall: each page of
rCis only needed once. Does not make sense to store multiple pages ofrCin the buffer.
If n == 2 (worst case):
- Read each page every time it’s requested.