PostgreSQL Page Internals
Page Representation

Each page is 8KB and contains:
- Header (free space pointers, flags, xact data).
- Array of (offset, length) pairs for tuples in page.
- Free space region (between array and tuple data).
- Actual tuples themselves (inserted from end towards start).
- (Optionally) region for special data (e.g. index data).
Large data items are stored in separate (TOAST) files.
Page-Related Data Types
// a Page is simply a pointer to start of buffer
typedef Pointer Page;
// indexes into the tuple directory
typedef uint16 LocationIndex;
// entries in tuple directory (line pointer array)
typedef struct ItemIdData {
unsigned lp_off:15, // tuple offset from start of page
lp_flags:2, // unused,normal,redirect,dead
lp_len:15; // length of tuple (bytes)
} ItemIdData;
typedef struct PageHeaderData
{
XLogRecPtr pd_lsn; // xact log record for last change
uint16 pd_tli; // xact log reference information
uint16 pd_flags; // flag bits (e.g. free, full, ...
LocationIndex pd_lower; // offset to start of free space
LocationIndex pd_upper; // offset to end of free space
LocationIndex pd_special; // offset to start of special space
uint16 pd_pagesize_version;
TransactionId pd_prune_xid;// is pruning useful in data page?
ItemIdData pd_linp[1]; // beginning of line pointer array
} PageHeaderData;
typedef PageHeaderData *PageHeader;
Page Operations
void PageInit(Page page, Size pageSize, ...)
- Initialise a
Pagebuffer to empty empty. - In particular, sets
pd_lowertopd_upper.
OffsetNumber PageAddItem(Page page, Item item, Size size, ...)
- Insert one tuple (or index entry) into a
Page.
void PageRepairFragmentation(Page page)
- Compact tuple storage to give one large free space region.
Types of Pages
PostgreSQL has two kinds of pages:
- Heap pages which contains tuples.
- Index pages which contain index entries.
Both kinds of pages have the same page layout. Main difference:
- Index entries tend to be smaller than tuples.
- Can typically fit more index entires per page.
TOASTing
TOAST = The Oversized-Attribute Storage Technique
- Handles storage of large attribute values (> 2KB).
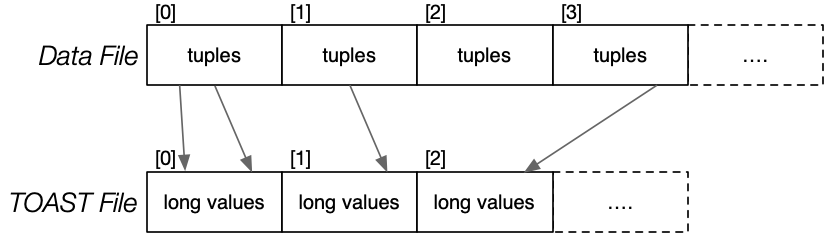
Large attribute values are stored in a separate file.
- Value of attribute in tuple is a reference to TOAST data.
- TOAST’d values may be compressed.
- TOAST’d values are stored in 2K chunks.
Strategies for storing TOAST-able columns:
PLAIN: allows no compression or out-of-line storage.EXTENDED: allows both compression and out-of-line storage.EXTERNAL: allows out-of-line storage but not compression.MAIN: allows compression but not out-of-line storage.